R & Spotify – Part 1: Long Distance Calling
Data Science meets Post-Rock…
Schon vor ein paar Monaten habe ich eine sehr witzige Punk-Rock-Datenanalyse entdeckt, die Salvino A. Salvaggio auf seinem R-Blog veröffentlicht hat. Der Blogpost besteht aus einer Reihe interessanter (und gut visualisierter) Statistiken über die Ramones (wie z.B. die Anzahl unterschiedlicher Akkorde im Zeitverlauf) sowie einer durchaus anspruchsvollen quantitativen Analyse der Lyrics. Seither stolpere ich immer wieder über „Analysen“, die auf Daten von Spotify beruhen (wie zum Beispiel die Versuche, die depressivsten bzw. fröhlichsten Songs von Radiohead ausschließlich auf der Grundlage von Daten zu identifizieren). Möglich ist das vor allem deshalb, weil Spotify einen Datenbank-Zugriff mittels Web-API ermöglicht (mehr Infos dazu gibt es hier). Und natürlich existieren mittlerweile mehrere Pakete für R, die eine bequeme Anbindung ermöglichen.
Als Daten- und Musikfreak musste ich mir das natürlich genauer anschauen. Als „Usecase“ dient dabei Long Distance Calling, eine Postrock-Band aus Münster (keine Ahnung, warum ich genau diese Band genommen habe – vermutlich weil sie gerade zufällig nebenher lief).
Um auf die Datenbank von Spotify zuzugreifen, nutze ich das Paket spotifyr von Charles Thompson. Das Paket ist (noch) nicht über CRAN erhältlich sondern auf GitHub gehostet. Die Installation erfolgt daher über devtools.
# devtools::install_github('charlie86/spotifyr')
library(spotifyr)Zusätzlich wird ein Spotify-Developer-Account benötigt, der sich in wenigen Minuten hier erstellen lässt. Für den Zugriff via spofityr werden die SPOTIFY_CLIENT_ID und die SPOTIFY_CLIENT_SECRET ID benötigt, die man nach der Anmeldung erhält.
Sys.setenv(SPOTIFY_CLIENT_ID = "HIER DIE ID EINGEBEN")
Sys.setenv(SPOTIFY_CLIENT_SECRET = "HIER DIE SECRET ID EINGEBEN")
access_token <- get_spotify_access_token(client_id = Sys.getenv('SPOTIFY_CLIENT_ID'), client_secret = Sys.getenv('SPOTIFY_CLIENT_SECRET'))
Et voilà – das war’s auch schon. Jetzt erstellen wir einen Data Frame, der die Audio-Features aller Long Distance Calling Songs enthält. Das funktioniert folgendermaßen:
ldc_df <- get_artist_audio_features('Long Distance Calling')
library(dplyr)
##
## Attache Paket: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
# Um die spätere Replizierbarkeit zu gewährleisten werden an dieser Stelle nur die
# Alben ausgewählt, die zum Zeitpunkt des Blogposts auch erschienen sind - also
# alle Alben, die vor 2018 erschienen sind...:
ldc_df <- ldc_df %>%
filter(album_release_year < "2018-01-01")
glimpse(ldc_df)
## Observations: 43
## Variables: 31
## $ artist_name <chr> "Long Distance Calling", "Long Distance C…
## $ artist_uri <chr> "3SiCxhceGZgzusCLHd4Zz6", "3SiCxhceGZgzus…
## $ album_uri <chr> "65OQXbKwC9pJbVFVQDXF60", "65OQXbKwC9pJbV…
## $ album_name <chr> "Avoid the Light", "Avoid the Light", "Av…
## $ album_img <chr> "https://i.scdn.co/image/74fec1bc8e6dd655…
## $ album_type <chr> "album", "album", "album", "album", "albu…
## $ is_collaboration <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
## $ album_release_date <chr> "2010", "2010", "2010", "2010", "2010", "…
## $ album_release_year <date> 2010-01-01, 2010-01-01, 2010-01-01, 2010…
## $ album_popularity <int> 37, 37, 37, 37, 37, 37, 25, 25, 25, 25, 2…
## $ track_name <chr> "Apparitions", "Black Paper Planes", "359…
## $ track_uri <chr> "6B48Yd5cXycAc4k6hdtjN3", "6ZvmAXqrALWGr0…
## $ track_number <int> 1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6, 7, 1,…
## $ disc_number <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ danceability <dbl> 0.253, 0.446, 0.590, 0.311, 0.265, 0.288,…
## $ energy <dbl> 0.666, 0.862, 0.792, 0.718, 0.674, 0.799,…
## $ key <chr> "A", "G", "D", "A", "A", "E", "D", "G", "…
## $ loudness <dbl> -8.485, -6.732, -8.609, -7.984, -8.118, -…
## $ mode <chr> "minor", "major", "major", "major", "mino…
## $ speechiness <dbl> 0.0427, 0.0409, 0.0414, 0.0406, 0.0413, 0…
## $ acousticness <dbl> 6.26e-02, 1.30e-05, 1.01e-03, 2.01e-03, 1…
## $ instrumentalness <dbl> 0.74800, 0.79100, 0.87900, 0.81700, 0.433…
## $ liveness <dbl> 0.1480, 0.0667, 0.1180, 0.1390, 0.0763, 0…
## $ valence <dbl> 0.0554, 0.1550, 0.5040, 0.1820, 0.0847, 0…
## $ tempo <dbl> 95.013, 133.524, 145.024, 140.011, 139.98…
## $ duration_ms <dbl> 736760, 437120, 475120, 626173, 468107, 5…
## $ time_signature <dbl> 4, 4, 4, 4, 4, 4, 4, 4, 4, 1, 4, 4, 4, 4,…
## $ key_mode <chr> "A minor", "G major", "D major", "A major…
## $ track_popularity <int> 28, 44, 26, 23, 31, 26, 26, 23, 20, 20, 2…
## $ track_preview_url <chr> "https://p.scdn.co/mp3-preview/f4ae1ad725…
## $ track_open_spotify_url <chr> "https://open.spotify.com/track/6B48Yd5cX…Wie die (R-typisch etwas kryptische) Ausgabe oben offenbart, enthält der Data Frame allerlei Daten – von Song- und Albennamen über Coverbilder bishin zu Spotify „Audio-Features“, wie z.B. der „Tanzbarkeit“ oder der „instrumentalness“ eines Songs (jeweils von 0 bis 1), das Tempo und die Grundtonart der jeweiligen Lieder. Nähere Details zu den Daten und vor allem zu den Audio-Features finden sich hier).
Als erstes interessiert mich, welche Songs von Long Distance Calling bei den Nutzern von Spotify am beliebtesten sind. Dazu nutze ich die Variable “track_popularity”“, die Werte zwischen 0 und 100 annehmen kann (wobei 100 die maximale Popularität signalisiert). Berechnet wird die”track popularity“” über einen Algorithmus, der auf der Abspielhäufigkeit eines Songs beruht, dabei aber aktuelle Streams deutlich höher gewichtet als frühere. Zur Visualisierung der “track popularity”" nutze ich ggplot2.
library(ggplot2)
ggplot(ldc_df, aes(track_popularity,
reorder(track_name, track_popularity),
fill = reorder(album_name, album_release_year))) +
labs(x = "Popularität", y = "Songs", fill = "Alben") +
geom_point(size = 2, shape = 21) +
theme(legend.position = c(0.75, 0.1),
legend.justification = c(0.55, 0.1),
legend.direction = "vertical",
legend.background = element_rect(fill="gray90", size=.5, linetype="dotted"),
axis.text = element_text(size=8)) 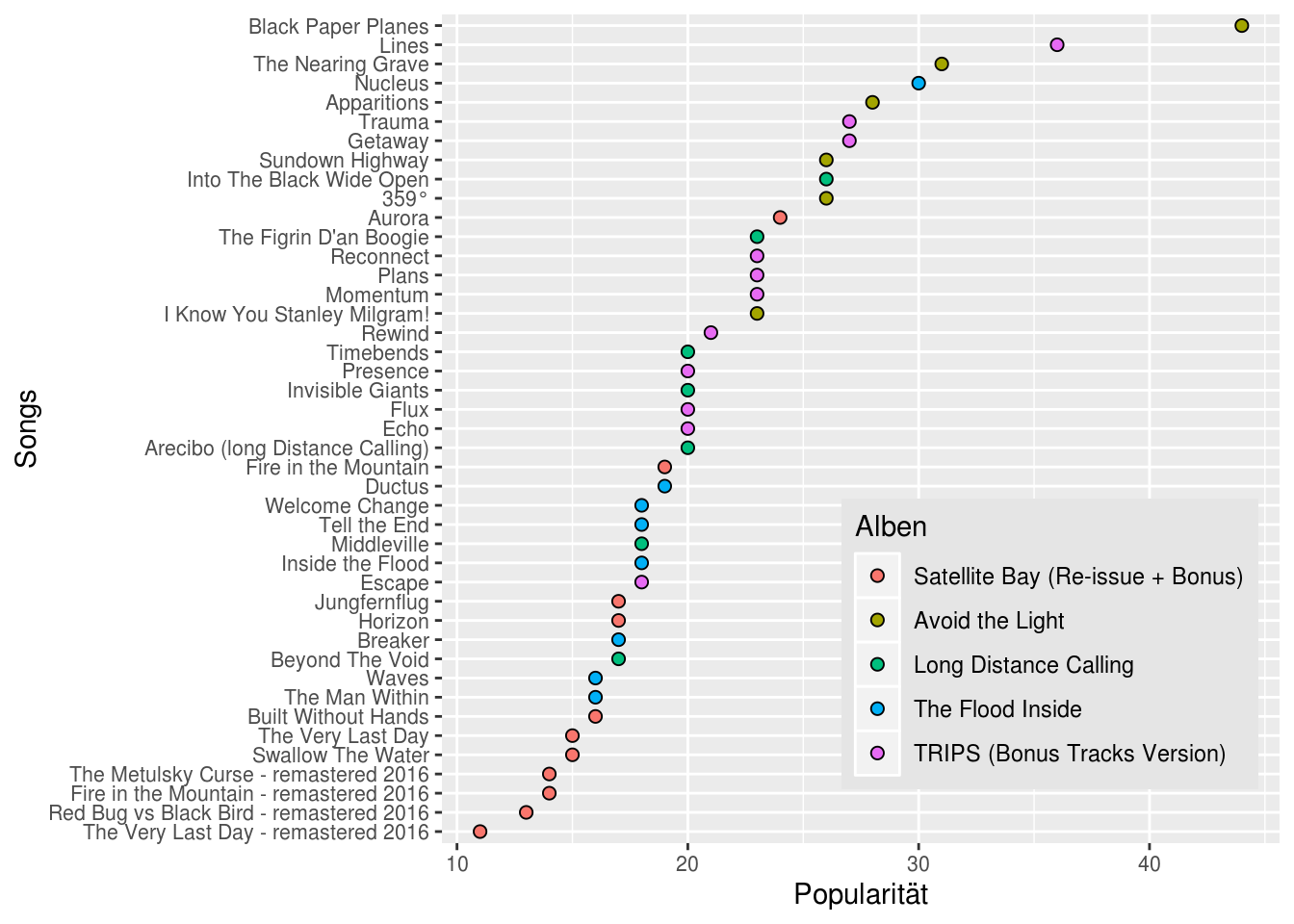
Der mit Abstand beliebteste Songs ist – tadaaa – Black Paper Planes. Soweit nicht überraschend. Einige meiner Lieblinge (z.B. Invisible Giants und Arecibo) finden sich dagegen vergleichsweise weit hinten. Zum Teil dürfte das darauf zurückzuführen sein, dass es sich hierbei um relativ alte Songs handelt und die Streams der jüngeren Vergangenheit überproportional hoch gewichtet werden (zum Teil mag es aber auch an meinem Geschmack liegen…).
Als nächstes interessiert mich, ob sich die musikalische Entwicklung der Band auch in den Daten widerspiegelt. Dazu sollte man wissen, dass sich auf den früheren Alben der Band nahezu ausschließlich ziemlich lange Instrumentalstücke finden; die Songs auf den letzten beiden Alben sind dagegen nicht nur kürzer sondern auch etwas „popliger“ – und sehr viel häufiger auch mit Gesang. Einen Überblick über die einzelnen Alben habe ich mir unter Zuhilfenahme einiger dplyr-Funktionen verschafft, die Visualisierung erfolgt wieder mittels ggplot.
library(dplyr)
library(tidyr)
library(lubridate)
##
## Attache Paket: 'lubridate'
## The following object is masked from 'package:base':
##
## date
ldc_agg <- ldc_df %>%
group_by(album_name) %>%
summarise(year = mean(year(album_release_year)),
tracks = n(),
mean_duration = mean(duration_ms/60000),
tempo = mean(tempo),
danceability = mean(danceability),
energy = mean(energy),
valence = mean(valence),
instrumentalness = mean(instrumentalness),
album_popularity = mean(album_popularity),
track_popularity = mean(track_popularity)) %>%
arrange(year)
ldc_agg
## # A tibble: 5 x 11
## album_name year tracks mean_duration tempo danceability energy valence
## <chr> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Satellite… 2006 11 8.18 121. 0.485 0.661 0.228
## 2 Avoid the… 2010 6 9.15 133. 0.359 0.752 0.199
## 3 Long Dist… 2011 7 8.02 144. 0.346 0.684 0.105
## 4 The Flood… 2013 8 6.93 114. 0.420 0.718 0.206
## 5 TRIPS (Bo… 2016 11 5.46 120. 0.492 0.701 0.273
## # … with 3 more variables: instrumentalness <dbl>, album_popularity <dbl>,
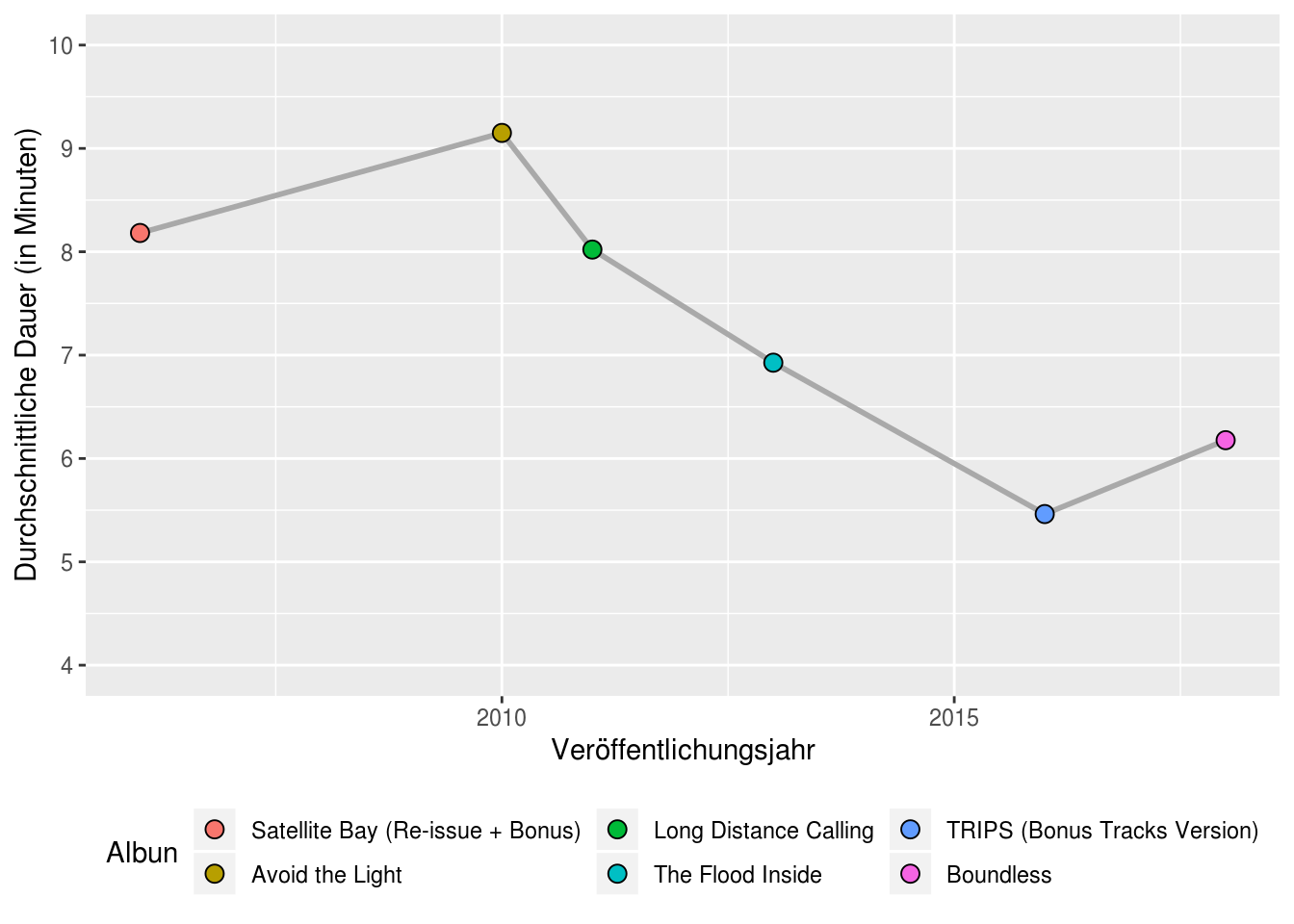
## # track_popularity <dbl>Die Tatsache, dass die Songs auf den letzten Alben deutlich kürzer geworden sind, wird in der Grafik unten sehr deutlich. Mit durchschnittlich 5,46 Minuten pro Song wird LDC ja langsam fast schon radiotauglich…
ggplot(ldc_agg) +
geom_line(aes(year, mean_duration), size = 1, color = "darkgrey") +
geom_point(aes(year, mean_duration, fill = reorder(album_name, year)), size = 3, shape = 21) +
labs(x = "Veröffentlichungsjahr",
y = "Durchschnittliche Dauer (in Minuten)",
fill = "Alben") +
scale_y_continuous(limits = c(4,10), breaks = seq(4,10,1)) +
theme(legend.position="bottom") +
guides(fill = guide_legend(nrow = 3))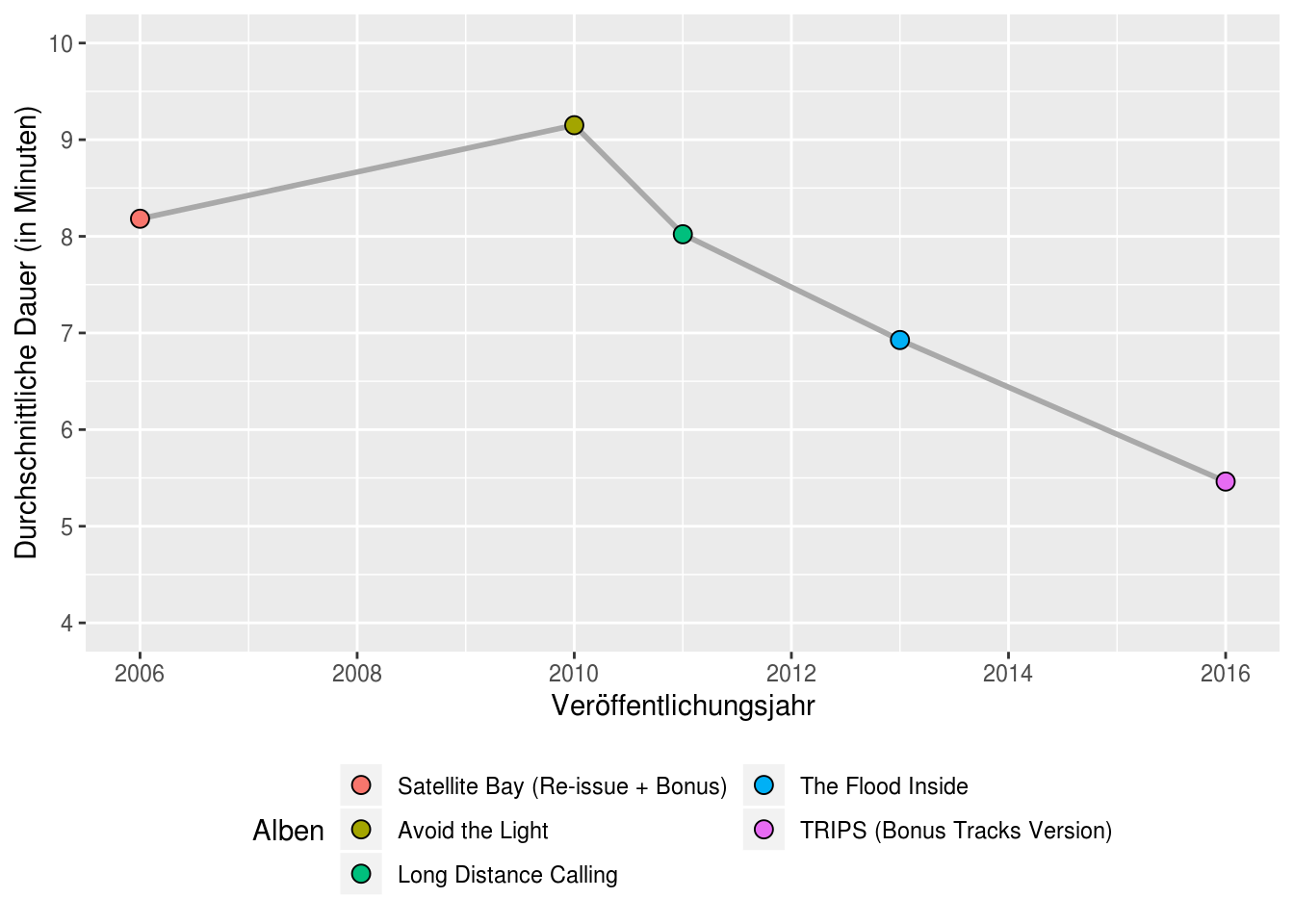
Zuletzt noch ein Blick auf einige „Audio Features“ wie „dance“, „energy“, „valence“ und „instrumentalness“:
ldc_audio <- ldc_agg %>%
select (album_name, year, danceability, energy, valence, instrumentalness) %>%
gather(variable, value, -c(album_name, year))
ggplot(ldc_audio) +
geom_line(aes(year, value, color = variable), size = 1.25) +
geom_point(aes(year, value, shape = reorder(album_name, year)), size = 2) +
labs(x = "Veröffentlichungsjahr",
y = "Durchschnittswert",
color = "Audio Feature",
shape = "Album") +
theme(legend.position="bottom",
legend.box = "vertical") +
guides(shape = guide_legend(nrow = 2))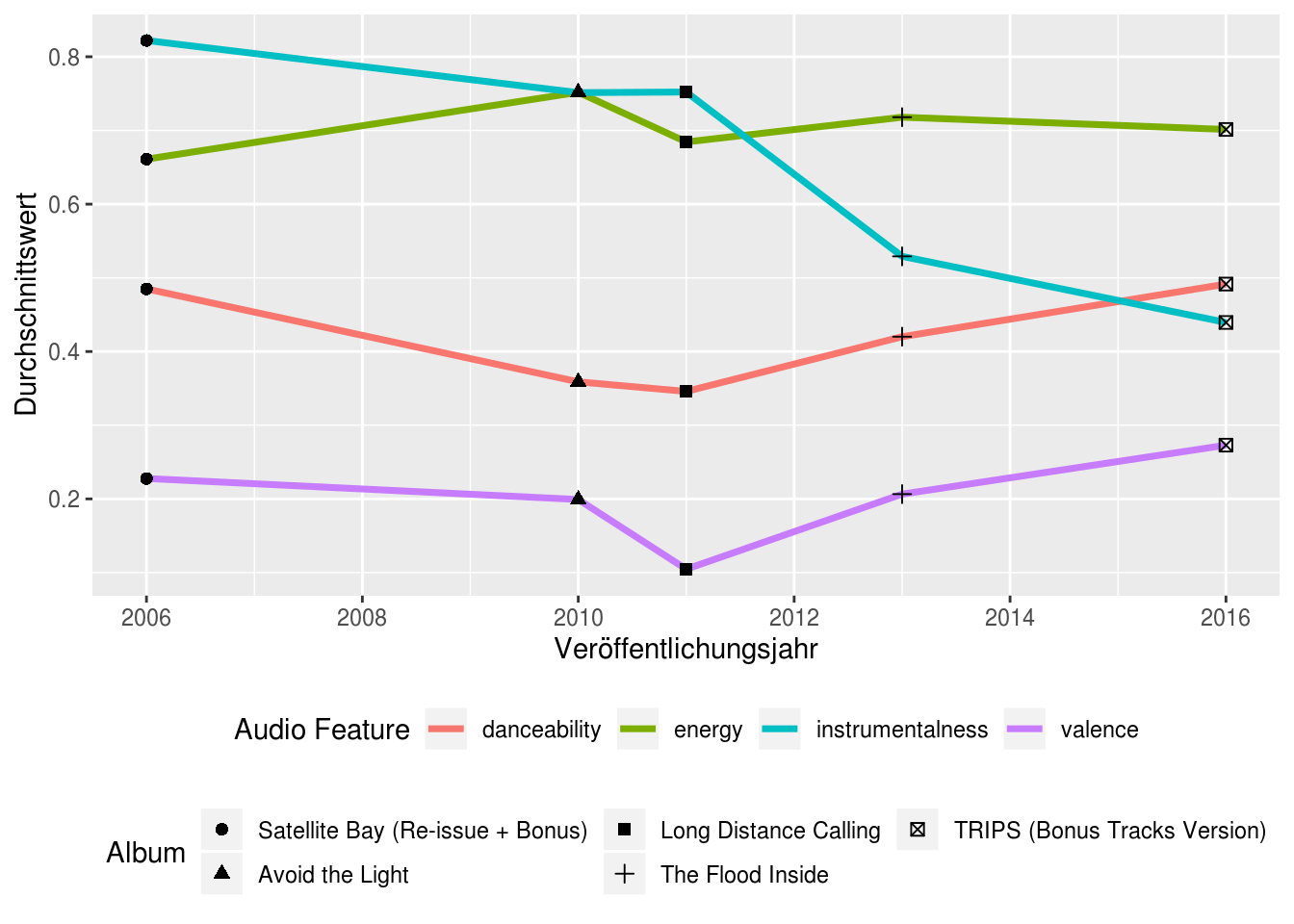
An der Entwicklung der Variable „instrumentalness“ wird die Abkehr von der reinen Instrumentalband zur „auch-Instrumentalband“ deutlich erkennbar. Zudem deuten die Daten darauf hin, dass die letzten beiden Alben etwas „fröhlicher“ („valence“) und „tanzbarer“ geworden sind. Auch das deckt sich mit meinem Eindruck, dass LDC zunehmend „poppiger“ geworden sind (bedauerlicherweise).
Mein erstes Fazit: Die Anbindung von R zur Spotify-Datenbank funktioniert bestens und die Daten sind durchaus interessant. Ich werde mich damit garantiert noch etwas intensiver auseinandersetzen – deswegen auch das „Part 1“ in der Überschrift.
Ein kleines Update im Mai 2018
Nachdem mit „Boundless“ (endlich) wieder ein reines Instrumentalalbum von Long Distance Calling erschienen ist, musste ich natürlich auch den Blogbeitrag nochmal aktualisieren. Und siehe da: Die Entwicklung zeigt sich klar in den Daten. Die „instrumentalness“ steigt deutlich an und das Album ist weniger „fröhlich“ und „tanzbar“. Ach, und länger sind die Songs auch wieder. So soll es sein :-):
ldc_df <- get_artist_audio_features('Long Distance Calling')
ldc_agg <- ldc_df %>%
group_by(album_name) %>%
summarise(year = mean(year(album_release_year)),
tracks = n(),
mean_duration = mean(duration_ms/60000),
tempo = mean(tempo),
danceability = mean(danceability),
energy = mean(energy),
valence = mean(valence),
instrumentalness = mean(instrumentalness),
album_popularity = mean(album_popularity),
track_popularity = mean(track_popularity)) %>%
arrange(year)
ldc_audio <- ldc_agg %>%
select (album_name, year, danceability, energy, valence, instrumentalness) %>%
gather(variable, value, -c(album_name, year))
ggplot(ldc_audio) +
geom_line(aes(year, value, color = variable), size = 1.25) +
geom_point(aes(year, value, shape = reorder(album_name, year)), size = 2) +
labs(x = "Veröffentlichungsjahr",
y = "Durchschnittswert",
color = "Audio Feature",
shape = "Album") +
theme(legend.position="bottom",
legend.box = "vertical")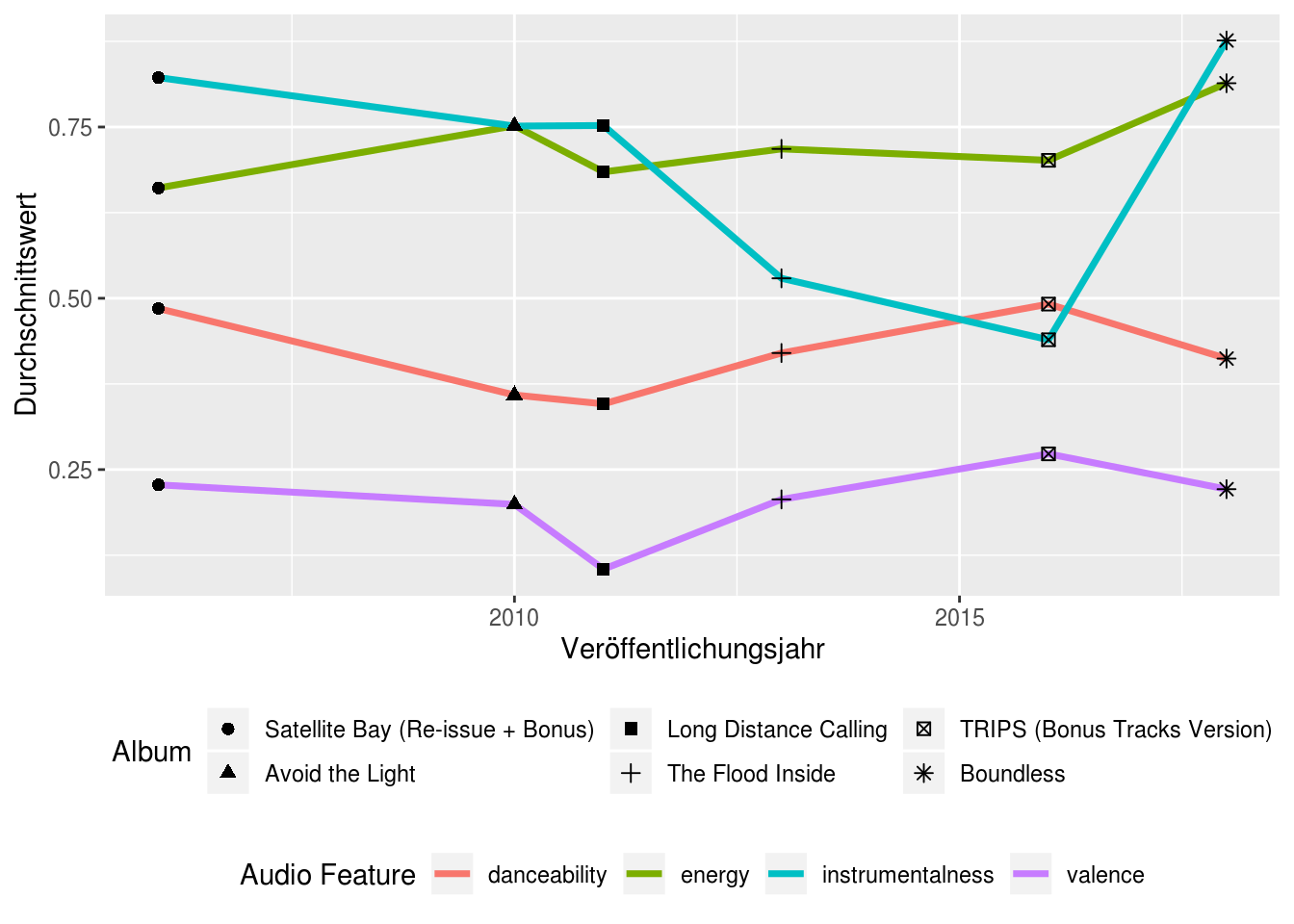
ggplot(ldc_agg) +
geom_line(aes(year, mean_duration), size = 1, color = "darkgrey") +
geom_point(aes(year, mean_duration, fill = reorder(album_name, year)), size = 3, shape = 21) +
labs(x = "Veröffentlichungsjahr",
y = "Durchschnittliche Dauer (in Minuten)",
fill = "Albun") +
scale_y_continuous(limits = c(4,10), breaks = seq(4,10,1)) +
theme(legend.position="bottom")